
Gdzieś w 1965 roku inżynierowie z Bell Labs mieli problem. Mieli dane. Mieli dyski. Ale nie mieli żadnego spójnego sposobu żeby jedno z drugim pogodzić. Każdy program trzymał pliki po swojemu, każdy system rozumiał je inaczej, a przeniesienie czegokolwiek między maszynami wymagało wiedzy tajemnej i trzech godzin cierpliwości.
Ktoś musiał zdecydować jak plik w ogóle powinien wyglądać od środka. Jak go znaleźć. Jak go zapisać. Jak wiedzieć że się skończył.
Te decyzje — podjęte pół wieku temu, przy zupełnie innych założeniach — nadal kształtują to co dzieje się kiedy zapisujesz dokument, robisz zdjęcie telefonem albo kopiujesz plik na pendrive.
Zanim był system plików, był chaos
Wczesne komputery nie miały systemu plików w sensie który znamy. Był dysk i były bloki danych. Program który chciał coś zapisać, musiał sam wiedzieć gdzie na dysku jest wolne miejsce — i sam to śledzić. Jeśli dwa programy nie dogadały się co do tego gdzie zapisują, nadpisywały sobie dane nawzajem. Bez ostrzeżenia, bez błędu, po prostu — dane poprzedniego znikały.
IBM w latach 60. wprowadził pierwsze formalne systemy zarządzania plikami dla mainframe'ów. Ale prawdziwy przełom przyszedł razem z Unixem — i z pomysłem który dziś wydaje się oczywisty, a wtedy był rewolucyjny: wszystko jest plikiem.
Nie tylko dokumenty. Nie tylko dane. Urządzenia, procesy, połączenia sieciowe — wszystko miało wyglądać jak plik i zachowywać się jak plik. Ten jeden pomysł uprościł projektowanie systemu operacyjnego o kilka rzędów złożoności i jest żywy do dziś w każdym Linuxie, macOS i wszelkim potomstwie Uniksa.
FAT: system który nie miał prawa działać tak długo
W 1977 roku Bill Gates i Marc McDonald napisali prosty system plików dla mikrokompiterów. Nazywał się FAT — File Allocation Table — i działał na tej samej zasadzie co spis treści w książce: osobna tabela mówiła gdzie na dysku zaczyna się każdy plik i gdzie kończy.
FAT był projektowany na dyskietki. Potem był FAT12, FAT16, FAT32 — każda kolejna wersja próbowała nadążyć za rosnącymi dyskami doklejając kolejne bity do adresowania. To trochę jak powiększanie mieszkania przez dobudowywanie kolejnych pokoi na zewnątrz — działa, ale nikt by tak nie zaprojektował czegoś od zera.
I tu leży paradoks FAT32. Sam standard obsługuje woluminy do 2 TB. Ale przez trzy dekady Windows odmawiał formatowania powyżej 32 GB — z powodu arbitralnego limitu wpisanego przez jednego inżyniera pewnego deszczowego dnia w 1994 roku. Dysk sformatowany w innym systemie operacyjnym Windows czytał bez problemu. Sformatować sam — nie chciał.
W kwietniu 2026 Microsoft w końcu to naprawił.
FAT32 w 2026 roku nadal ma znaczenie, bo rozumieją go wszystkie systemy operacyjne, wszystkie konsole, wszystkie aparaty, większość przemysłowego sprzętu pomiarowego. To lingua franca nośników danych. I właśnie dlatego jego ograniczenia bolały tak długo.
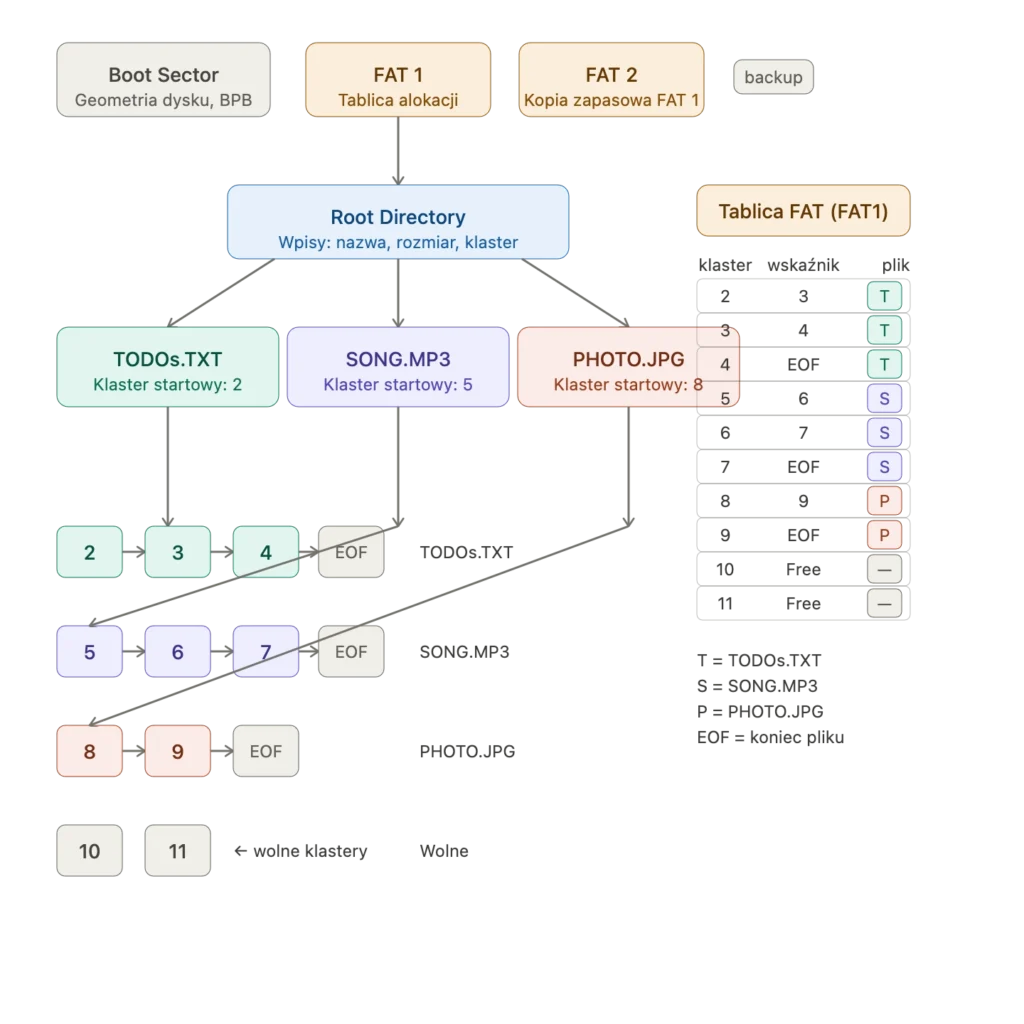
NTFS: kiedy "tymczasowe rozwiązanie" trwa trzydzieści lat
Windows NT potrzebował nowoczesnego systemu plików. FAT był za stary, za ograniczony, nie obsługiwał uprawnień, nie radził sobie z awariami, nie skalował się na serwery. Microsoft stworzył NTFS — New Technology File System — i zaprezentował go w 1993 roku jako fundament nowej generacji systemu.
NTFS był technologicznie imponujący. Obsługiwał uprawnienia na poziomie pliku, journaling który pozwalał odtwarzać stan po awarii, kompresję, szyfrowanie, strumienie alternatywne pozwalające przechowywać dodatkowe metadane przy pliku. W 1993 roku to był znaczący krok naprzód.
Był też zaprojektowany jako rozwiązanie na dekadę, może dwie. Potem miał przyjść następca, prawdopodobnie OFS — Object File System — który miał zmienić sposób myślenia o danych. OFS nigdy nie wyszedł poza prototypy. NTFS trwa.
Niewielu ludzi wie że każdy plik w NTFS ma ukryte strumienie danych — osobne zestawy danych przywiązane do pliku, niewidoczne w standardowym eksploratorze. Windows używa ich żeby oznaczyć pliki pobrane z internetu jako "niebezpieczne" (to właśnie odpowiada za komunikat "czy na pewno chcesz uruchomić ten plik"). Przez lata był to też ulubiony trick malware'u który chował kod w strumieniach alternatywnych.
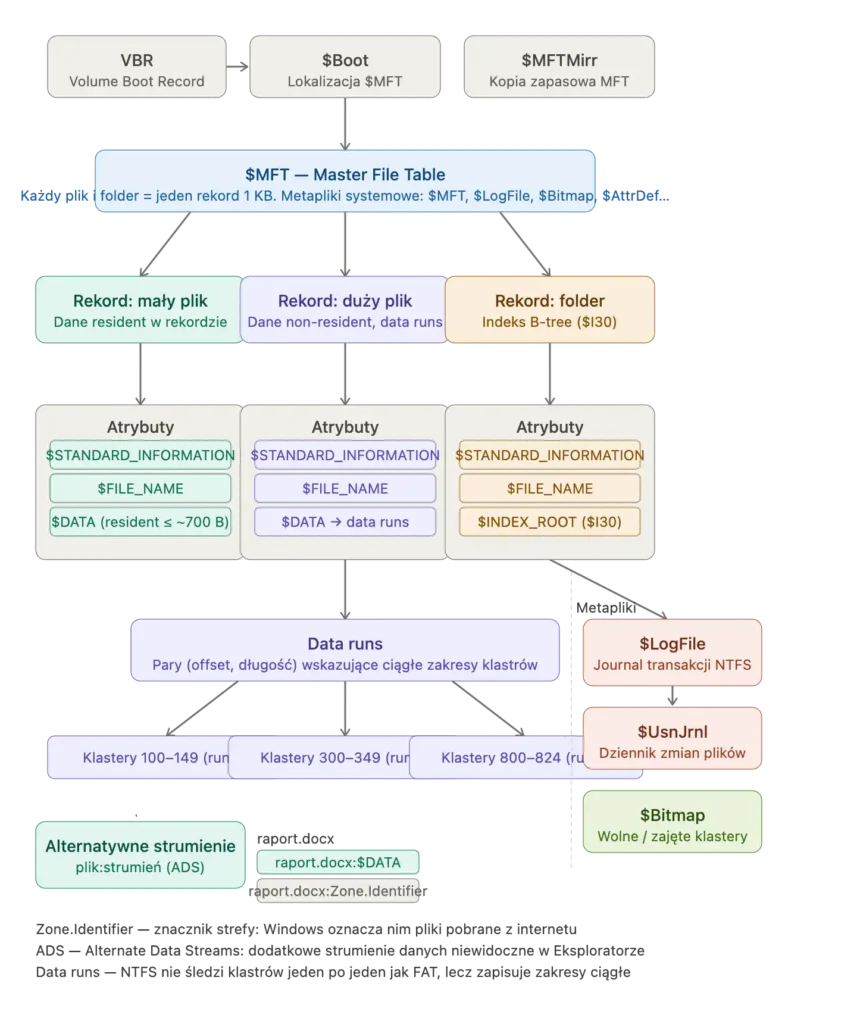
ext4: system który nie chciał się skończyć
Linux zaczął od Minix FS — systemu plików pożyczonego z systemu edukacyjnego, z limitem 16 MB na plik i 64 MB na partycję. To wystarczyło na początku. Potem nie wystarczało wcale.
Przyszedł ext, potem ext2, ext3, ext4. Każda wersja dodawała coś czego poprzedniej brakowało — ext3 dodał journaling, ext4 podniósł limity do wartości które trudno osiągnąć w praktyce (16 TB na plik, 1 exabajt na wolumin), poprawił wydajność na dużych katalogach, dodał sumę kontrolną dziennika.
ext4 jest domyślnym systemem plików w większości dystrybucji Linuxa od 2008 roku. Przez szesnaście lat nic lepszego nie wyparło go z pozycji domyślnej opcji — co jest zarówno komplementem dla jakości ext4, jak i ilustracją jak trudno jest zastąpić coś co działa wystarczająco dobrze.
Oficjalny następca, ext5, nigdy nie powstał. Zamiast tego społeczność Linuxa podzieliła się między btrfs i XFS — i żaden z nich nie zdominował rynku w sposób który ext4 zdominował go po prostu przez bycie wszędzie.
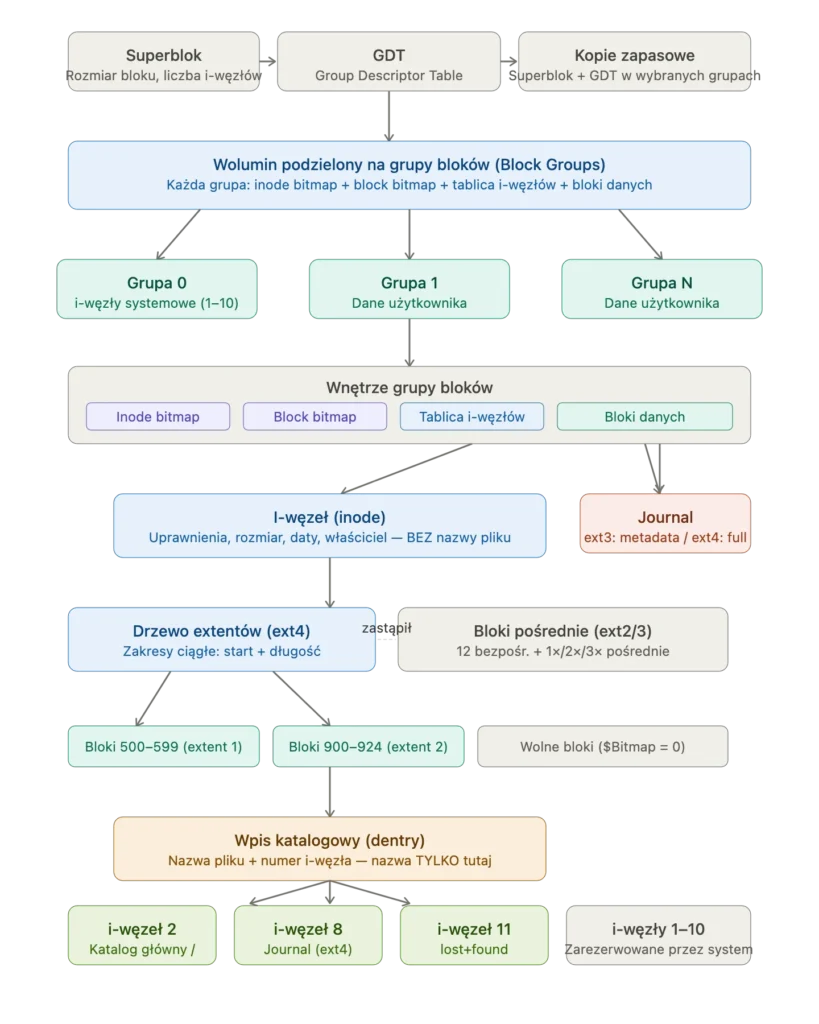
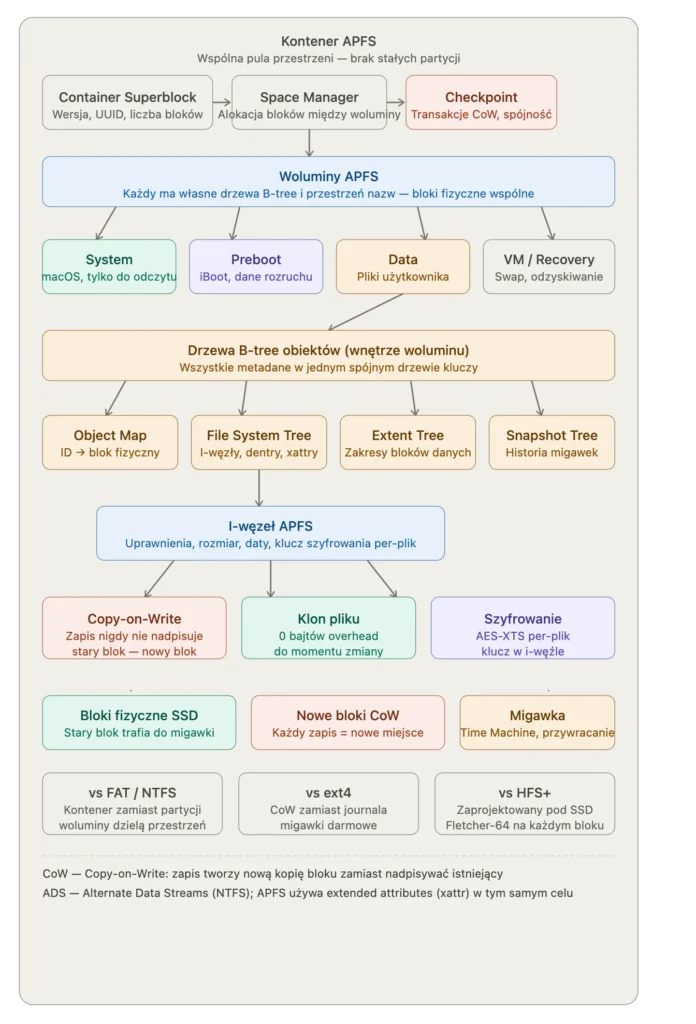
APFS: kiedy Apple postanowiło przepisać wszystko
Przez dekady Maki używały HFS — Hierarchical File System — stworzonego w 1985 roku z myślą o 3,5-calowych dyskietkach. Potem HFS+, który wyszedł w 1998 i był przez Apple utrzymywany do 2017. Dwadzieścia lat z systemem plików zaprojektowanym na sprzęt który nie istniał już od dekady.
W 2017 roku Apple wydało APFS — Apple File System — zaprojektowany od zera z myślą o SSD. To ważna różnica. Tradycyjne systemy plików zakładały że zapis jest wolniejszy niż odczyt i optymalizowały pod ten scenariusz. SSD nie ma mechanicznych głowic, dostęp losowy jest tak samo szybki jak sekwencyjny, i całe to założenie się sypie.
APFS obsługuje natywne szyfrowanie dla każdego pliku osobno, migawki systemu (to co pozwala Time Machine cofnąć macOS do stanu z poprzedniego tygodnia), klony plików które nie zajmują dodatkowego miejsca dopóki dane się nie rozejdą, i transakcje — jeśli operacja na wielu plikach nie dobiegnie końca z powodu awarii zasilania, system wie że operacja była atomowa i albo cała się udała, albo żadna jej część.
Migracja z HFS+ na APFS przez Apple Update przeszła dla większości użytkowników niezauważalnie. To rzadkość — ciche zastąpienie fundamentu systemu bez przerwy w działaniu — i wskazuje jak dużo pracy poszło w kompatybilność wsteczną.
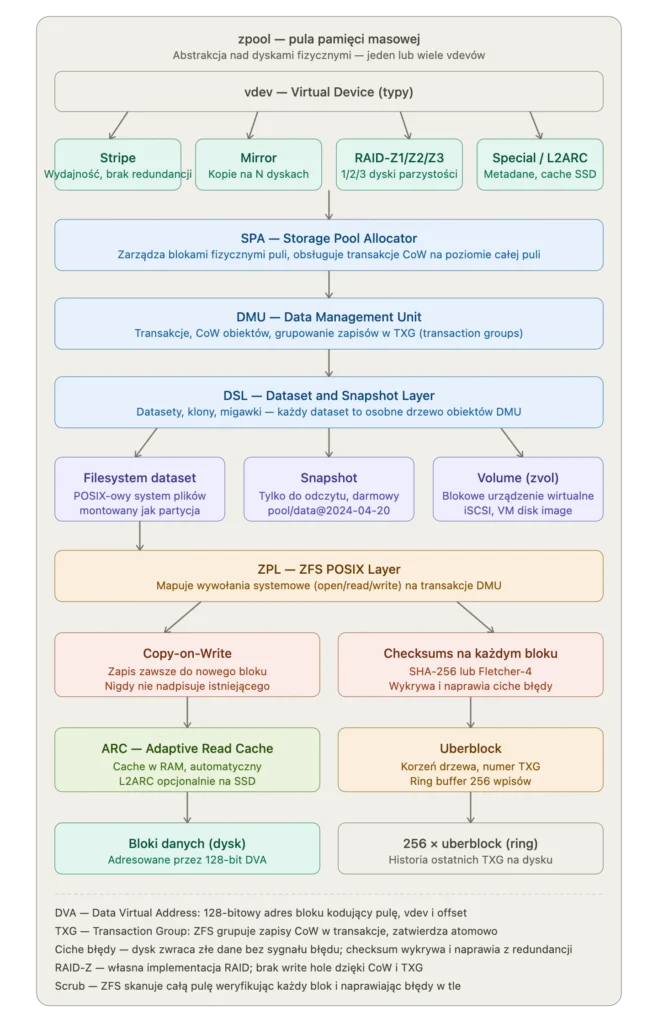
ZFS: system który traktuje twoje dane jak problem matematyczny
ZFS powstał w Sun Microsystems w 2001 roku. Jeff Bonwick i jego zespół zaczęli od pytania: co jeśli założymy że dyski kłamią?
Nie "co jeśli dysk się psuje" — to znany problem z prostym rozwiązaniem (RAID). Ale: co jeśli dysk po cichu zwraca złe dane nie informując o błędzie? Co jeśli dwa dyski w macierzy RAID jednocześnie zwracają różne, oba błędne, wartości dla tego samego sektora?
To nie jest scenariusz akademicki. Ciche uszkodzenia danych — silent data corruption — są realnym problemem szczególnie w środowiskach z dużą ilością dysków pracujących latami. RAID tego nie wykrywa, bo RAID zakłada że dysk albo działa poprawnie albo zgłasza błąd. Nie ma procedury dla dysku który milcząco kłamie.
ZFS sumuje kryptograficznie każdy blok danych i przechowuje te sumy osobno. Przy każdym odczycie sprawdza czy dane zgadzają się z sumą. Jeśli nie zgadzają — szuka poprawnej kopii w macierzy, naprawia blok i loguje incydent. Bez przerwy w działaniu, bez utraty danych, z pełnym audytem co się wydarzyło.
ZFS nie jest domyślnym systemem plików w żadnej głównej dystrybucji Linuxa — przez lata blokował to konflikt licencyjny między licencją CDDL Sun a GPL kernela. Jest domyślny w FreeBSD i w systemach pamięci masowej takich jak TrueNAS. Na Linuxie działa przez OpenZFS i jest popularny wszędzie tam gdzie dane naprawdę muszą przetrwać — archiwa, serwery mediów, środowiska produkcyjne.
Co łączy te wszystkie decyzje
Systemy plików to decyzje o tym co jest prawdą. Jak dane wyglądają na dysku, jak się je odnajduje, jak system wie że są spójne, co się dzieje kiedy coś pójdzie nie tak w połowie zapisu.
Każdy z opisanych systemów był odpowiedzią na inne pytanie. FAT odpowiadał na pytanie jak zarządzać dyskietkami w erze zanim pamięć była tania. NTFS odpowiadał na pytanie jak zbudować system plików dla serwerów z uprawnieniami i odpornością na awarie. APFS odpowiadał na pytanie jak zoptymalizować system plików pod flash zamiast talerzowych dysków. ZFS odpowiadał na pytanie co zrobić kiedy nie możesz ufać własnym dyskom.
Każdy też niósł założenia które z czasem stawały się ograniczeniami. FAT nie przewidział dysków powyżej kilkuset megabajtów. NTFS nie przewidział SSD. HFS+ nie przewidział urządzeń mobilnych z ograniczoną przestrzenią.
Decyzje podejmowane przy założeniu "to wystarczy na razie" potrafią przetrwać długo po tym jak "razie" minęło. FAT32 przeżył trzydzieści lat z limitem z 1994 roku. HFS+ działał w Makach przez dwie dekady dłużej niż ktokolwiek planował.
Następnym razem kiedy plik nie chce się skopiować na pendrive, bo jest za duży na FAT32 — to właśnie jest ten moment gdzie historia systemów operacyjnych dotyka codzienności bardziej bezpośrednio niż większość ludzi podejrzewa.